上海交通大学 机器智能与交互实验室
Bo Zhao is an Associate Professor (Tenure Track) at School of Artificial Intelligence, Shanghai Jiao Tong University. Before, he was with BAAI as Principal Investigator, leading DCAI group. He received Ph.D. from The University of Edinburgh and M.Eng. from Peking University. His research interests include Embodied AI, Multimodal LLM and Data-centric AI. He received ICML 2022 Outstanding Paper Award. He was the only nominee of The University of Edinburgh for Informatics-Europe Best Dissertation Award 2023. He received NSFC fundings on MLLMs and Dataset Condensation. He served as an Area Chair for NeurIPS'25/24 and BMVC'24, and organizers for DD workshops at CVPR'24 and ECCV'24.
赵波是上海交通大学人工智能学院长聘教轨副教授、博导,入选国家级青年人才项目。曾担任智源研究院(BAAI)数据智能研究中心负责人、首席研究员。曾获得爱丁堡大学博士学位和北京大学硕士学位。研究方向包括具身智能、多模态大模型和数据智能(DCAI)等。曾获 ICML 2022 杰出论文奖,并作为爱丁堡大学唯一提名人入围2023年欧洲信息学最佳博士论文奖候选名单。主持多项国自然基金委科研项目。担任 NeurIPS'25/24和BMVC'24 领域主席,并于 CVPR'24 和 ECCV'24 组织数据集蒸馏研讨会。
I am working on Embodied AI, MLLM and Data-centric AI. Collaborations are welcome. Feel free to contact me. I am recruiting Ph.D./Master Students and Research Assistants/Interns. If you are interested, please read the Recruiting page (top-right).
实验室研究方向:具身智能,多模态大模型,数据智能等。实验室常年招收硕博士生以及实习生,详情请阅读右上角招聘页面。
News:
- Two papers from our team got accepted as CVPR Oral! Only 96 CVPR Orals this year.
- Welcome Dr. Gen Li to our lab for a visit of months.
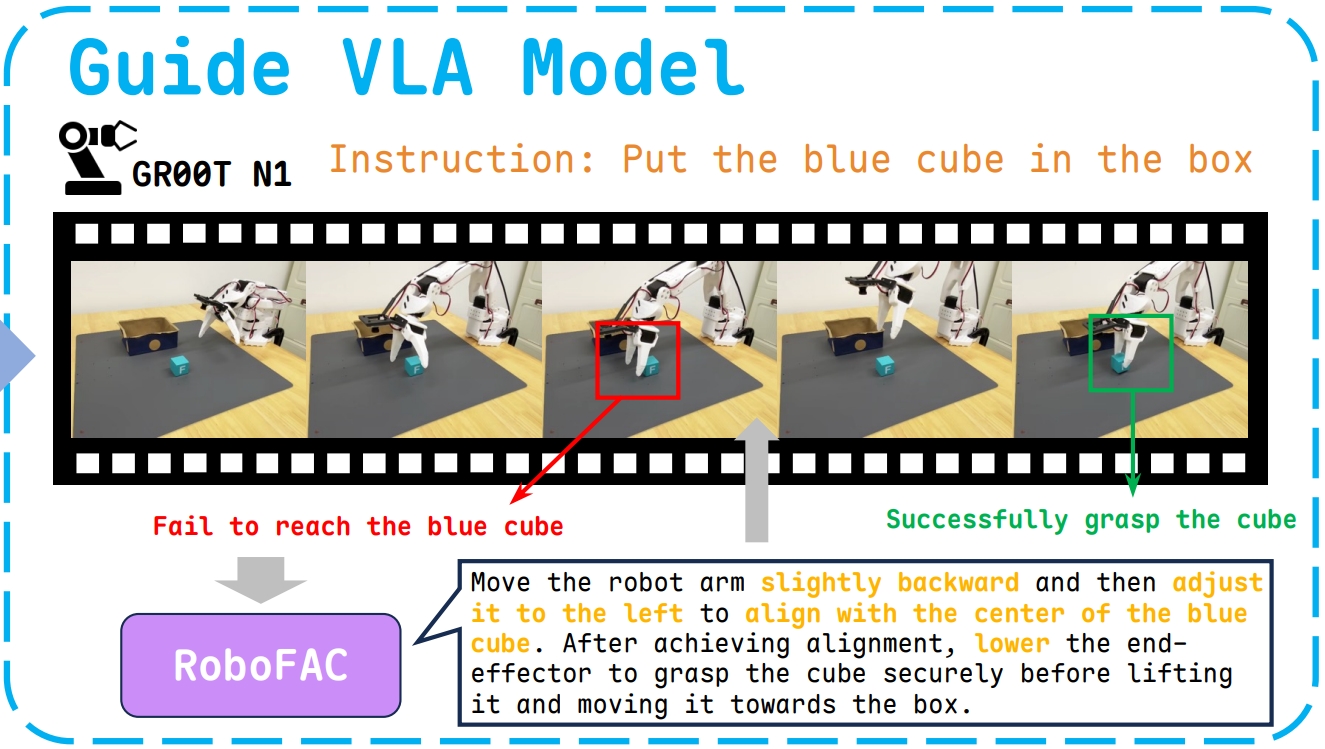
We present RoboFAC with 9,440 erroneous manipulation trajectories and 78,623 QA pairs across 16 diverse tasks and 53 scenes, and a VLM model for robot failure analysis and correction.
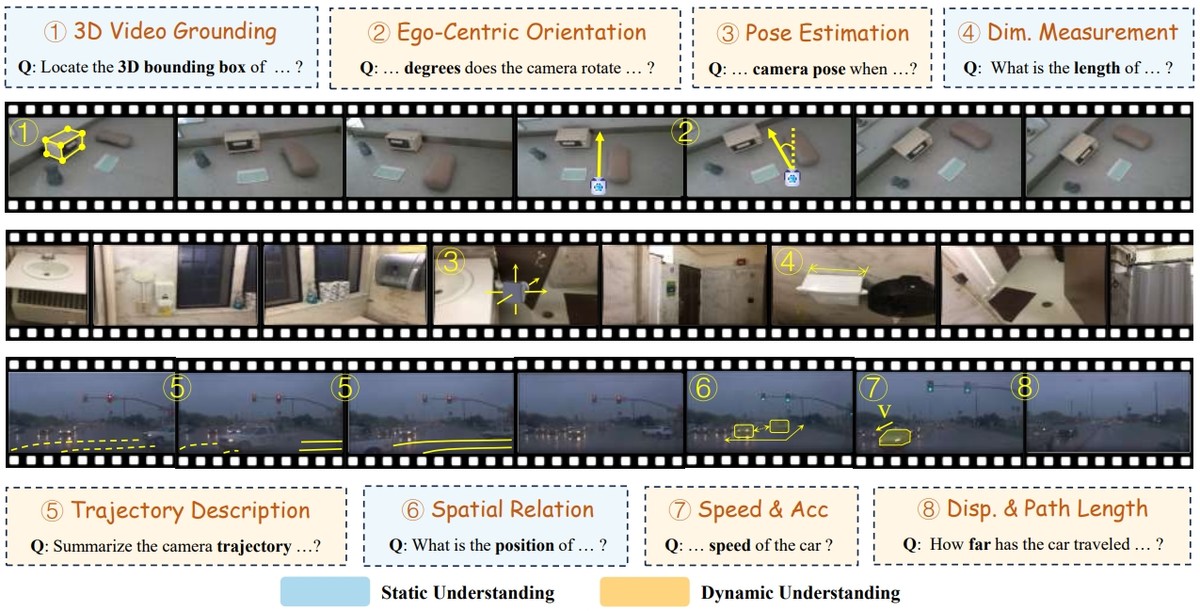
STI-Bench: a benchmark designed to evaluate MLLMs’ spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects.
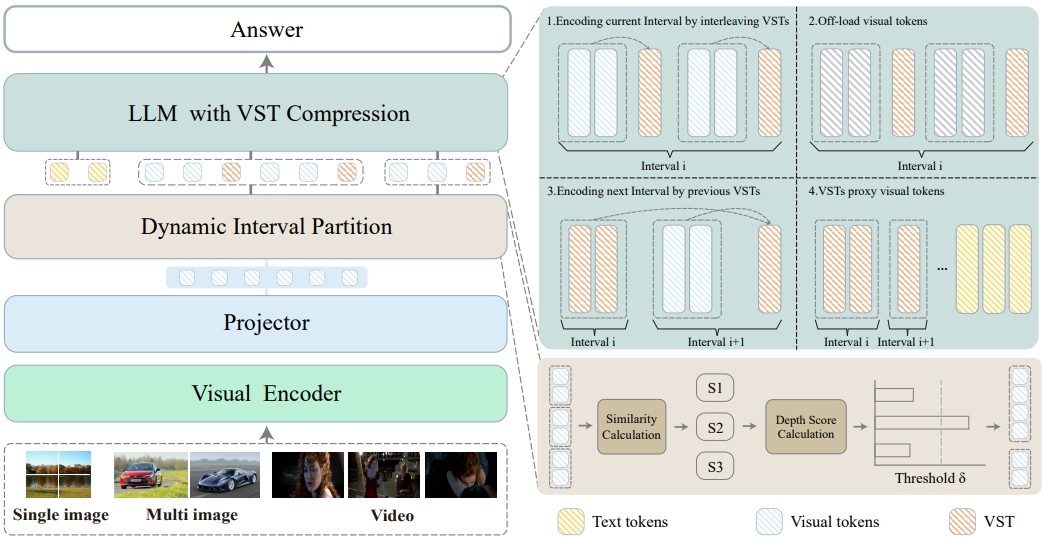
[CVPR'25 Oral] We propose Video-XL, a novel approach that leverages MLLMs’ inherent KV sparsification capacity to condense the visual input realizes outstanding cost-effectiveness, enabling high-quality processing of thousands of frames on a single A100 GPU.
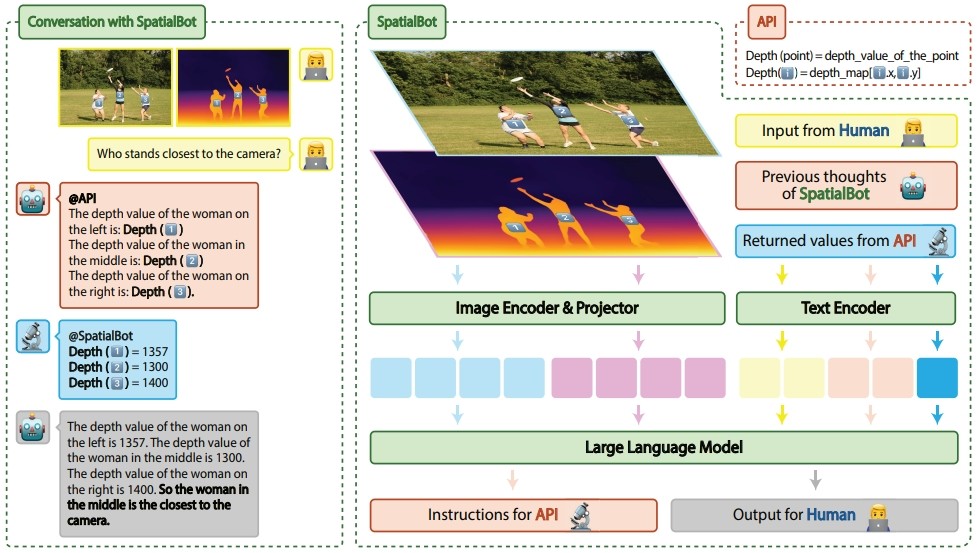
[ICRA'25] We propose SpatialBot, a family of state-of-the-art VLMs, for effective depth understanding and thus precise robot manipulating in embodied AI by training on our constructed SpatialQA and SpatialQA-E datasets.

[ECCV'24] We introduces Omni6DPose, a substantial benchmark featured by its diversity in object categories, large scale, and variety in object materials, across 581 instances in 149 categories.
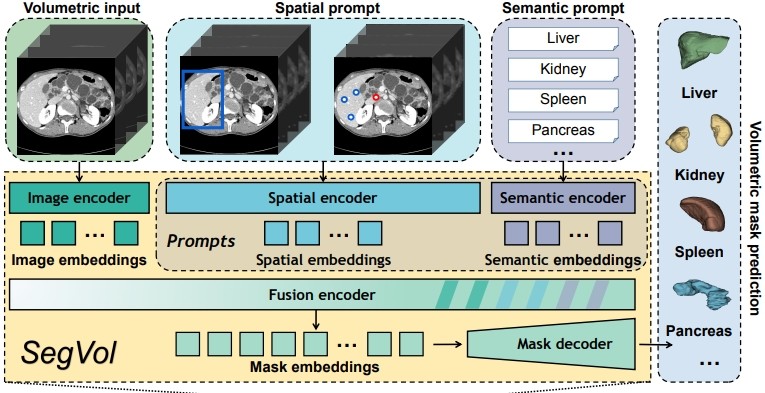
[NeurIPS'24 Spotlight] We propose a 3D foundation segmentation model, named SegVol, supporting universal and interactive volumetric medical image segmentation, supporting the segmentation of over 200 anatomical categories.
[CVPR 2025 Oral (Top 7‰)] Towards Universal Dataset Distillation via Task-Driven Diffusion Ding Qi, Jian Li, Junyao Gao, Shuguang Dou, Ying Tai, Jianlong Hu, Bo Zhao, Yabiao Wang, Chengjie Wang, Cairong Zhao. Coming soon Oral Ratio: 96/13008 [ACL 2025 Oral] MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval Junjie Zhou, Yongping Xiong, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, Defu Lian. Coming soon [ICML 2025] BOOD: Boundary-based Out-Of-Distribution Data Generation Qilin Liao, Shuo Yang, Bo Zhao, Ping Luo, Hengshuang Zhao. Coming soon [ICRA 2025] NaVid-4D: Unleashing Spatial Intelligence in Egocentric RGB-D Videos for Vision-and-Language Navigation Haoran Liu* Weikang Wan*, Xiqian Yu*, Minghan Li*, Jiazhao Zhang, Bo Zhao, Zhibo Chen, Zhongyuan Wang, Zhizheng Zhang, He Wang [IJCV 2025] Image Captions are Natural Prompts for Training Data Synthesis Shiye Lei*, Hao Chen*, Sen Zhang, Bo Zhao†, Dacheng Tao† Coming Soon [NeurIPS 2024] Fetch and Forge: Efficient Dataset Condensation for Object Detection Ding Qi, Jian Li, Jinlong Peng, Bo Zhao, Shuguang Dou, Jialin Li, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Cairong Zhao [ECCV 2024] Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking Jiyao Zhang*, Weiyao Huang*, Bo Peng*, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, Hao Dong [RSS 2024] RAG-Driver Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model Jianhao Yuan, Shuyang Sun, Daniel Omeiza, Bo Zhao, Paul Newman, Lars Kunze, Matthew Gadd [CVPR 2023 Highlight (Top 3%)] Accelerating Dataset Distillation via Model Augmentation Lei Zhang*, Jie Zhang*, Bowen Lei, Subhabrata Mukherjee, Xiang Pan, Bo Zhao, Caiwen Ding, Yao Li, Dongkuan Xu [ICML 2022 Outstanding Paper Award (Top 2‰)] Privacy for Free: How does Dataset Condensation Help Privacy Tian Dong; Bo Zhao; Lingjuan Lyu [CVPR 2022] CAFE: Learning to Condense Dataset by Aligning Features Kai Wang*; Bo Zhao*; Xiangyu Peng; Zheng Zhu; Shuo Yang; Shuo Wang; Guan Huang; Hakan Bilen; Xinchao Wang; and Yang You [ACM TOG 2018 & SIGGRAPH 2019] EasyFont: A Style Learning based System to Easily Build Your Large-scale Handwriting Fonts Zhouhui Lian; Bo Zhao; Xudong Chen; Jianguo Xiao [SIGGRAPH ASIA 2016] Automatic Generation of Large-scale Handwriting Fonts via Style Learning Zhouhui Lian; Bo Zhao; Jianguo Xiao

